背景
1.Mybatis generator为mybatis生成了大量并没有实际使用的代码,实际发现只有 selectByExample,insertSelective 两个方法使用较多,而且为每个实体类生成一个 Example 类。 Example 这个类是大量相似的代码,完全可以抽象统一起来
2.还有生成不同风格的 DynamicSql 风格的mapper 层代码,混乱可读性差。
框架选型
jpa
jpa只需要简单生成entity,mapper 层继承 org.springframework.data.jpa.repository.JpaRepository 接口,只需要写方法名,就有了单表操作的能力,比起Mybatis generator 少了大量的不必要代码。
entity
1 |
|
单表操作
方法名字只需要遵守命名规范,就可以完成单表操作。以下相当于select * from order_refund where order_refund_no =?
1 | public interface OrderRefundMapper extends JpaRepository<OrderRefund, Long>{ |
分页
只需要在参数重加上 Pageable 返回值使用 Page 就可完成分页,注意 jpa中的page 是从0开始,而不是1。
1 | public interface OrderRefundMapper extends JpaRepository<OrderRefund, Long>{ |
自定义sql和返回对象
JPQL查询
使用自定义对象来接收结果,支持JPQL查询,但是不支持原生sql
对象定义如下
1 |
|
JPQL查询
1 | public interface OrderRefundMapper extends JpaRepository<OrderRefund, Long> { |
原生sql
使用原生sql 必须定义接口来收集结果或者使用List<Object[]>
1 | public interface CustomizeResultInterface { |
1 | //原生sql |
分页
1 | //原生sql |
动态sql
1 | OutInstruct outInstruct = new OutInstruct(); |
Jpa 中 Example 中的功能有限,不支持非字符串的范围查询,只支持等值查询。如果需要可以采用下面的方案
多继承一个接口
1 | public interface OrderRefundMapper extends JpaRepository<OrderRefund, Long> ,JpaSpecificationExecutor<OrderRefund> |
使用 根据条件动态拼接sql
1 | orderRefundMapper.findAll((Specification<OrderRefund>) (root, query, criteriaBuilder) -> { |
连表查询
举个 onetoMany的栗子:
定义指令单实体类:
1 |
|
定义出库指令单详情实体:
1 |
|
@JoinColumn中name 字段为详情表的外键字段(不必真的在数据库建立外键,逻辑外键即可),referencedColumnName 字段为主表的 主键(同样不必真的是数据库的主键,逻辑主键即可)
@OneToMany(fetch = FetchType.LAZY) 这里定义为懒加载,JOIN FETCH中的fetch,是可以在单条select语句中,初始化对象中的关联或集合。
如示例中OutInstruct的dtList成员,它是lazy成员,默认情况下是不会被初始化的,也就是说如果通过getDtList()访问成员的时候,就会报LazyInitializationException的异常。
例如以下代码会抛出LazyInitializationException的异常:
1 | OutInstruct outInstruct = new OutInstruct(); |
如果想有连表查详情的能力,比较简单的方式有以下两种:
第一:
在方法上加上事物的注解:如果在同一个事务上下文内,是可以获取到lazy成员的,但在长事务或者多线程的场景下,这种方法就不合适。
第二:
使用JpaSpecificationExecutor api手动fetch相关懒加载成员:
1 | Optional<OutInstruct> outInstruct1 = outInstructMapper.findOne((Specification<OutInstruct>) (root, query, criteriaBuilder) -> { |
mybatis+mybatiscodehelper 插件
http://118.24.53.162/#/methodNameToSql
通过方法名字 生成sql,其规范和jpa的一样。比起Mybatis generator 少了大量的不必要代码。缺点就是每一种查询条件都需要写一个sql,没有动态拼接sql 的能力,可能会有大量的单表操作的方法。
分页功能可以基于mybatis的分页插件。
mybatis plus
Mybatis 本身就是自定义sql 的这里主要就说一下 mybatis plus 对单表操作及动态sql 的封装,其中的com.baomidou.mybatisplus.core.mapper.BaseMapper
com.baomidou.mybatisplus.extension.service.IService 这两个接口提供了大量单表的curd,基本能满足所有的单表操作要求。
动态sql
QueryWrapper,UpdateWrapper提供了动态select ,update的功能。
1 | QueryWrapper<OutInstruct> queryWrapper=new QueryWrapper<>(); |
分页
定义插件
1 |
|
在参数列表中加入IPage 就可完成分页
1 | @Select("select * from out_instruct where id > #{identity}") |
对比
接入成本
- Jpa:换了持久层框架,会修改所有持久层代码,接入成本比较大
- mybatiscodehelper 插件:和原来一样只是安装一个插件,基本没有接入成本
- mybatis plus :可以和原有的mybatis兼容,基本没有接入成本
学习成本
- Jpa:换了持久层框架,如果之前没有用过,有一定的学习成本。
- mybatiscodehelper 插件:原生mybatis,没有学习成本。
- mybatis plus:和原来的mybatis差不多,基本没有学习成本。
易用性
- Jpa:单表操作只需要按照规范写方法名,支持动态sql,分页。
- mybatiscodehelper 插件:单表操作只需要按照规范写方法名,不支持动态sql。
- mybatis plus:提供了丰富的单表操作方法, 支持动态sql。
性能
单条数据的操作逻辑都是一样的,只有批量数据的操作逻辑不太一样,这里以批量插入为例,比较一下不同框架的性能
建立测试表
1 | -- auto-generated definition |
| mybatis plus | jpa | 自定义sql | |
|---|---|---|---|
| 10000条 | 时间太久不想等 | 时间太久不想等 | 9s |
| 5000条 | 406 s | 时间太久不想等 | 7s |
| 2000条 | 148 s | 252 s | 6s |
why?
mybatis plus慢在哪里
查看源码 mybatis plus 中的批量插入 使用的是批量模式
1 | sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH); |
把SQL语句发个数据库,数据库预编译好,数据库等待需要运行的参数,接收到参数后一次运行,ExecutorType.BATCH只打印一次SQL语句,多次设置参数步骤。
mybatis plus 源码简单来看相当于以下代码:
1 | try (SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH);) { |
sql日志中 也证实只发了一句sql 多次发送参数的过程
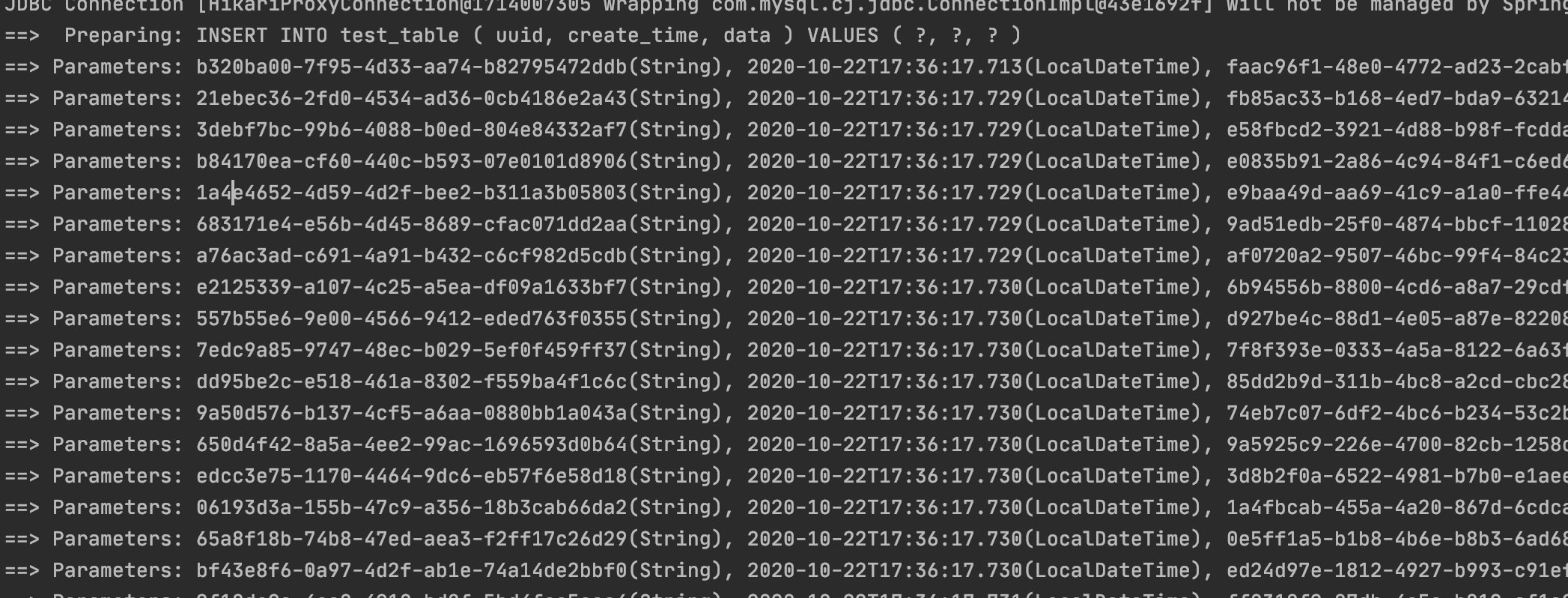
翻译成原始的jdbc就是这样:
1 | String sql="INSERT INTO test_table ( uuid, create_time, data ) VALUES ( ?, ?, ? )"; |
jpa 慢在哪里
查看jpa 中的源码
发现循环调用save 方法,真的过分,慢的合情合理
1 |
|
自定义sql快在哪里
自定义sql insert()values (),(),() 只执行一句sql 快的飞起,但是有一点需要注意, sql 的长度是有限制的,mysql默认接受sql的大小是1048576(1M)
结论
jpa,mybatis-plus,虽然很方便,提供了很多但表操作的api,以及动态sql的支持,但是要小心使用他们的批量操作的功能,性能上比起自定义sql差很多。